Kamery endoskopowe (i inne)
Autor: dr inż. Marcin Just, dr inż. Michał Tyc (DiagNova Technologies)Kamera jest pierwszym i podstawowym elementem niezbędnym do przeniesienia obrazu na dysk komputera. Podstawowy etap procesu przetwarzania – pomiar ładunku elektrycznego zgromadzonego w poszczególnych komórkach detektora (przetwornika) kamery – ciągle odbywa się w sposób analogowy, więc z punktu widzenia samego procesu przetwarzania sygnału świetlnego na postać elektryczną wszystkie kamery są analogowe, czyli sygnał reprezentowany w nich jest poprzez określony w pewnym przedziale poziom napięcia lub prądu. Aby komputer mógł wykonać swoją część pracy, analogowy sygnał z przetwornika kamery musi zostać przetworzony na postać cyfrową. Tu możliwe są dwa rozwiązania:
- sygnał z przetwornika kamery zostaje wzmocniony, odpowiednio przygotowany i w sposób analogowy przeniesiony kablem do oddzielnej karty grabującej, w której zostaje zamieniony na postać cyfrową i przekazany do komputera,
- przetwornik kamery sam zamienia sygnał na postać cyfrową, albo sygnał z przetwornika kamery zostaje zamieniony w samej kamerze na postać cyfrową i w tej postaci z pominięciem osobnego grabbera doprowadzony do komputera.
Kamery z zastosowanym drugim rozwiązaniem potocznie określa się mianem kamer cyfrowych.
Przetworniki CCD z CMOS
Sercem kamery jest przetwornik zamieniający obraz w sygnały elektryczne. W zdecydowanej większości kamer ma on postać matrycy miniaturowych elementów światłoczułych. Przetworniki wykonywane są w dwóch różnych technologiach: CCD i CMOS. Technologie te zasadniczo różnią się wykonaniem i działaniem. W dużym uproszczeniu przyjąć można, że przetworniki typu CMOS przejmują na siebie zdecydowanie więcej „obowiązków” związanych z przetwarzaniem obrazu – zawierają zwykle wbudowane przetworniki zamieniające analogowy sygnał elektryczny z komórek światłoczułych na postać cyfrową, zapewniają prostą realizację funkcji migawki itp. Ze względu na większe skomplikowanie, matryce CMOS zwykle znacznie bardziej się nagrzewają podczas pracy i wykazują większe różnice parametrów pomiędzy poszczególnymi komórkami światłoczułymi. Powoduje to wzrost szumów cieplnych, objawiający się większym tzw. prądem ciemnym, czyli prądem generowanym przez komórki światłoczułe przy braku oświetlenia. Zjawiska te znacznie straciły ostatnio na znaczeniu i brać je pod uwagę należy praktycznie jedynie przy bardzo długich czasach naświetlania charakterystycznych dla wykonywania zdjęć przy złych warunkach oświetleniowych (zwłaszcza zdjęć astronomicznych). Technologia CCD pozbawiona jest dużej części wad technologii CMOS, jednak odbywa się to kosztem skomplikowania układu towarzyszącego przetwornikowi obrazu. Budowa przetworników typu CCD predestynuje je zwłaszcza do budowy kamer pracujących z przeplotem, przetworniki CMOS zwykle są typu progresywnego.
Kamery progresywne a z przeplotem
Ten podział jest szczególnie istotny. Działanie kamer progresywnych istotnie różni się od działania kamer z przeplotem. Zdecydowanie starsza jest technologia z przeplotem. Charakteryzuje się ona tym, że obraz przetwarzany jest przez przetwornik dwuetapowo – najpierw linie parzyste matrycy przetwornika, następnie nieparzyste (lub na odwrót). Szczególnie ważne jest tu rozdzielenie czasowe obu etapów. Odbiór linii parzystych i nieparzystych oddzielony jest co najmniej o czas potrzebny na zebranie i przetworzenie danych ze wszystkich linii – zwykle jest to około 1/100–1/50 sek. Uzyskuje się w ten sposób właściwie nie jeden obraz o pełnej rozdzielczości, ale dwa obrazy o połowicznej rozdzielczości (półobrazy) dodatkowo przesunięte w pionie o wysokość jednej linii, zaś w czasie rozłożone równomiernie. Technika ta doskonale sprawdza się w przypadku oglądania obrazu z takiej kamery na ekranie klasycznego telewizora (lub monitora) kineskopowego. Obraz wyświetlany jest wtedy dwa razy częściej (nie 25, lecz 50 klatek/sek.) z odpowiednim pionowym przesunięciem, dając w przypadku obrazów nieruchomych wrażenie pełnej rozdzielczości, zaś w przypadku obrazów ruchomych – wrażenie lepszej płynności. Inaczej sprawa wygląda, gdy obraz z takiej kamery jest prezentowany na ekranie z pełną rozdzielczością w tym samym momencie, bez czasowego rozdzielenia połówkowych klatek. Tylko w przypadku obrazów całkowicie statycznych (np. obraz preparatu pod mikroskopem) można mówić wtedy o realnym uzyskaniu z kamery typu „z przeplotem” pełnej deklarowanej rozdzielczości. Gdy kamera taka rejestruje obraz ruchomy, na klatkach filmu pojawiają się tzw. artefakty, zdecydowanie pogarszające jakość obrazu (przykład na rys. 1).

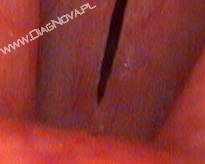
.jpg)
Rys. 1. Zjawisko przeplotu w materiale wideo (endoskopowe nagranie fałdów głosowych w czasie fonacji)
Dodatkowe pogorszenie obrazu z przeplotem następuje po przeskalowaniu (rys. 2).
.jpg)
Rys. 2. Pogłębienie efektu przeplotu po przeskalowaniu obrazu
Istnieją algorytmy obróbki obrazu, pozwalające na usunięcie wspomnianych zaburzeń, ale bez względu na swoją złożoność, zapewniają uzyskanie pełnej rozdzielczości w pionie tylko w przypadku szczęśliwego zbiegu okoliczności (albo nie wystąpiło przesunięcie obrazu w pionie pomiędzy półobrazami, albo przesunięcie to wynosi dokładnie wielokrotność wysokości linii obrazu). Porównanie działania kilku algorytmów usuwania przeplotu przedstawiono na rys. 3.


Proste usuwanie co drugiej linii


Rys. 3. Porównanie trzech algorytmów usuwania przeplotu ilustrujące dla rzeczywistego obrazu wideo praktycznie minimalną użyteczność stosowania metod zaawansowanych w stosunku do prostego usuwania co drugiej linii
Stosowanie zaawansowanych algorytmów usuwania przeplotu w celu uzyskania pełnej rozdzielczości obrazu okazuje się w praktyce bezzasadne i powinno być stosowane jedynie w przypadku starych nagrań w celu usunięcia (a raczej zredukowania) artefaktów. Działanie zaawansowanych algorytmów nie poprawia zwykle nawet wyglądu klatek prawie statycznych (rys. 4).
Proste usuwanie co drugiej linii
.jpg)

Rys. 4. Porównanie działania algorytmu zaawansowanego i prostego usuwania linii dla obrazu pozornie statycznego
W przypadku sygnału z kamery z przeplotem znacznie atrakcyjniejsze jest podwajanie liczby klatek na sekundę w połączeniu z delikatnym przesuwaniem w pionie sąsiednich półobrazów, symulujące oglądanie obrazu na ekranie klasycznego monitora kineskopowego. Uzyskuje się wówczas w czasie oglądania zarejestrowanego filmu jednocześnie wrażenie lepszej płynności i lepszej rozdzielczości. Kosztem praktycznie bardzo nieznacznej utraty ostrości pionowej uzyskuje się obraz bez przeplotu i dodatkowo większą liczbę klatek, pozwalającą na łatwiejsze wybranie klatki zawierającej najciekawszą treść (rys. 5).
.jpg)
.jpg)
Rys. 5. Działanie mechanizmu połączonego usuwania przeplotu i podwajanie liczby klatek: u góry oryginalna sekwencja wideo, u dołu – po operacji usuwania przeplotu z podwajaniem liczby klatek
Z każdej kamery z przeplotem uzyskać można obraz bez przeplotu, wybierając którąś z mniejszych rozdzielczości (np. 352×288 zamiast 720×576). Metoda ta zasadniczo powinna być stosowana jedynie w przypadku mocy obliczeniowej komputera niewystarczającej do tego, by mógł sobie poradzić z większą rozdzielczością. Różnica jakości obrazu uzyskiwanego dzięki metodzie usuwania przeplotu z powielaniem klatek a prostej redukcji rozdzielczości jest widoczna (rys. 6), dodatkowo nie uzyskuje się podwojenia klatek.
.jpg)
.jpg)
Rys. 6. Porównanie obrazów o różnych rozdzielczościach
Zdecydowanie lepiej dopasowaną do specyfiki nowoczesnych monitorów komputerowych i telewizorów jest technologia progresywna. Ze względu na subtelności budowy przetworników obrazu progresywnych i z przeplotem, kamery progresywne wymagają nieco więcej światła do dobrego działania. W skrajnych przypadkach może to być współczynnik rzędu 2.
Jeśli niedobór światła nie jest przeszkodą, zdecydowanie korzystniejszym rozwiązaniem są kamery progresywne. Dysponują one zwykle też większą rozdzielczością.
Kamery cyfrowe a analogowe
Jak już było wspomniane, kamery cyfrowe od analogowych zasadniczo różnią się sposobem przesyłania sygnału do komputera (cyfrowy lub analogowy). Ze względu na postępującą miniaturyzację, wzrost mocy obliczeniowej i mniejsze wymaganie na prąd zasilający elementów elektronicznych, integrowanie z kamerą dodatkowo przetwornika analogowo-cyfrowego pełniącego funkcję grabbera nie powoduje obniżenia jego jakości. Przesył danych cyfrowych jest znacznie mniej wrażliwy na zakłócenia i jest rozwiązaniem przyszłościowym. Wszystko to pozwalałoby sądzić, że zdecydowanie korzystniej jest stosować kamery cyfrowe. Nie ma jednak róży bez kolców. W przypadku klasycznego grabbera, umieszczonego w komputerze stacjonarnym jako karta rozszerzeń lub w notebooku jako ExpressCard (lub starszego typu karta PCMCIA), przesył danych cyfrowych odbywa się w sposób bardzo wydajny, bez zbytniego angażowania procesora komputera. Cała moc obliczeniowa procesora może być wówczas spożytkowana do obróbki obrazów w celu poprawy ich jakości, zmniejszenia rozmiaru, kompresji itp. Paradoksalnie, najstarsze (i zwykle najtańsze) rozwiązanie – kamera analogowa zastosowana z kartą grabbera zapewnia najlepsze wykorzystanie mocy komputera. Kamera cyfrowa może być podłączona z użyciem specjalnej dedykowanej karty rozszerzeń wkładanej do komputera, ale zazwyczaj podłączenie kamery cyfrowej odbywa się z wykorzystaniem jednego z portów komputera – USB, FireWire (IEEE 1394a lub 1394b) lub Gigabit Ethernet. O ile porty FireWire i Gigabit Ethernet zapewniają obsługę przychodzącego strumienia danych bez zbytniego obciążania procesora, to niestety najpopularniejszy z nich – USB (USB 2.0) wymaga nieustannej kontroli połączenia przez procesor i zarezerwowania sporej części jego mocy obliczeniowej, która nie może być już wykorzystana do obróbki obrazów. Dodatkowo, spośród wymienionych standardów, USB 2.0 zapewnia najmniejszą praktyczną przepustowość dla danych – w praktyce około 30 MB (megabajtów) na sekundę (teoretycznie nieco więcej niż 50 MB). Ze względu na rozpowszechnienie, USB 2.0 jest w tej chwili zdecydowanie najczęściej stosowane i decydując się na to rozwiązanie trzeba uwzględnić większe wymagania co do mocy obliczeniowej komputera i ograniczenia związane z przepustowością tego łącza. Problem przepustowości łącza USB opisany zostanie w dalszej części dokumentu, w tym momencie wspomnieć wystarczy, że przy rozdzielczości 720×576 pikseli przez łącze USB 2.0 przekazać można około 25 klatek/sek. (zatem wystarcza to zaledwie do przekazania standardowego obrazu telewizyjnego w stosowanym w Polsce systemie PAL), przy rozdzielczości 640×480 około 30, ale już przy rozdzielczości 1280×960 – tylko 7,5 klatki/sek. Port FireWire posiada w wersji podstawowej przepustowość zbliżoną do portu USB (praktycznie około 40 MB/sek.), a w wersji rozszerzonej (1394b) około dwukrotnie większą, dodatkowo w standard ten wpisana z założenia jest pewna kompresja danych pozwalająca nawet na przenoszenie danych w formacie HD (wysokiej rozdzielczości).
Wielkość (przekątna) przetwornika i sprawność kwantowa
Potocznie (głównie w odniesieniu do cyfrowych aparatów fotograficznych) mówi się, że „małe” matryce szumią. Jest w tym stwierdzeniu sporo prawdy. Nie chodzi tu jednak o to, że małe matryce generują dużo zakłóceń (szumów); one są w stanie generować jedynie mały sygnał. Przy małym sygnale wszystkie szumy związane z konwersją światła na sygnały elektryczne nabierają większego znaczenia. Szumy pojawiają się bezpośrednio przy konwersji światła na ładunek elektryczny poszczególnych komórek matrycy kamery, pojawiają się też w związku z losowym generowaniem ładunków w komórkach matrycy (zależne od temperatury – im wyższa, tym ich więcej, stąd do niedawna matryce typu CMOS, z powodu ich silniejszego nagrzewania się, uważane były za bardziej szumiące).
Szumów jest wiele rodzajów, ale przy uwzględnieniu specyfiki pracy kamery generującej obraz wideo w czasie rzeczywistym, największe znaczenia mają szumy związane z kwantowym charakterem światła i samej konwersji światła na ładunek elektryczny. I, co jest bardzo istotne – szumy te nie zależą od producenta matrycy, kamery itp. Jest to zjawisko fizyczne, którego ominięcie w zwykłych przetwornikach stosowanych w klasycznych kamerach jest niemożliwe. W uproszczeniu te nieusuwalne podstawowe szumy osiągają wartość równą pierwiastkowi z wartości ładunku elektrycznego wygenerowanego w komórce kamery przez padające światło.
W tym momencie należy sobie zdać sprawę z tego, że zwykła kamera jest miejscem, gdzie normalny człowiek spotyka się ze zjawiskami kwantowymi. Światło postrzegane jest na ogół jako coś „ciągłego”. To, że interpretować można je jako strumień cząstek, na pierwszy rzut oka wydaje się czystą abstrakcją, z którą styczność można mieć jedynie w wielkim laboratorium. Tymczasem, podczas pracy kamery, podczas zbierania jednego obrazu stanowiącego jedną klatkę, do każdej komórki kamery docierają całkowicie policzalne liczby cząstek światła – fotonów. I nie mówimy tutaj o miliardach – to są tysiące, w najlepszym przypadku setki tysięcy. Tylko część tych fotonów wygeneruje elementarny ładunek (elektron) zwiększający łączny ładunek komórki kamery (ten współczynnik to sprawność kwantowa przetwornika, i zwykle wynosi od 0,2 do 0,5), a szumy w uproszczeniu stanowić będą pierwiastek z liczby wygenerowanych ładunków. Przy założeniu, że przeciętna kamera generuje w czasie zbierania jednego obrazu około 10000 ładunków w każdej komórce przetwornika, to szum stanowi około 100 ładunków (upraszczając) i odstęp od szumów (stosunek sygnału, czyli wytworzonego ładunku, do szumów) jest też jedynie równy 100 – a jest to poziom już wykrywalny przez oko ludzkie na zdjęciu. Jak łatwo zauważyć, stosunek sygnału do szumu rośnie proporcjonalnie do pierwiastka wytworzonego ładunku.
Sposób na niskie szumy jest więc prosty – należy dążyć do uzyskania jak największej liczby ładunków wygenerowanych w komórkach kamery. Wiąże się to z potrzebą uzyskania wysokiej sprawności kwantowej, ale przede wszystkim z koniecznością dotarcia do przetwornika jak największej liczby fotonów! Tak więc kluczową sprawą okazuje się oświetlenie. Im lepsze, tym więcej fotonów dotrze do przetwornika kamery. Dużą rolę odgrywa też jakość obiektywów czy optyki endoskopowej w medycynie – muszą przepuszczać dużo światła. I w tym momencie dochodzi się do sedna sprawy – komórki matrycy przetwornika kamery mają ściśle ograniczoną pojemność. Nie zgromadzą więcej wygenerowanych ładunków (a zatem nie przyjmą więcej fotonów) niż jest określone w specyfikacji producenta przetwornika. Przekroczenie tej liczby powoduje charakterystyczne przebarwienia, białe plamy prześwietleń itp. Pojemność komórki kamery zależy z reguły od jej powierzchni. Im większa komórka, tym lepszy może dawać maksymalny odstęp od szumów. A powierzchnia komórki zależy w pewnym niewielki stopniu od typu przetwornika (CMOS czy CCD, progresywny czy z przeplotem), zaś głównie od powierzchni całego przetwornika i liczby komórek (czyli rozdzielczości). Pozornie mogłoby się wydawać, że duża rozdzielczość przetwornika kamery wiąże się bezpośrednio z większymi szumami. Jednakże obraz o dużej rozdzielczości zawsze można na drodze obróbki komputerowej przeskalować do mniejszej rozdzielczości odpowiednio zmniejszając szumy (uśredniając jasności sąsiednich pikseli), tak więc, choć duża rozdzielczość zwiększa nieco szumy, jest to związane ze zjawiskami drugiego rzędu – choćby wspomnianymi szumami termicznymi, czy stopniem wykorzystania powierzchni jednej komórki przetwornika (piksela), który jest nieco gorszy w kamerach o większej rozdzielczości. Krytycznie istotna jest powierzchnia przetwornika – albo kilku przetworników. Jeśli w kamerze dla każdego koloru podstawowego zastosowany został osobny przetwornik, to ich powierzchnia sumuje się; przykładem mogą tu być popularne kamery 3CCD.
W praktyce w kamerach (w tym również medycznych) stosuje się zwykle przetworniki o przekątnych w zakresie od 1/6 cala do około 2/3 cala. Przykładowo, zakładając tę samą liczbę pikseli przetwornika i skrajne stosowane normalnie rozmiary – 1/6 cala i 2/3 cala, uzyskuje się stosunek powierzchni równy 16 (!), stąd w prosty sposób dochodzi się do 16 razy większej pojemności komórki kamery 2/3 cala i z tego do 4 razy lepszych jej parametrów szumowych. Tyle zyskuje się na większym przetworniku, natomiast zysk związany z najlepszym producentem w stosunku do najgorszego obecnie w zastosowaniach popularnych jest mniej więcej rzędu 1,5. Ciągnąc porównania dalej – kamera z trzema przetwornikami 1/4 cala (3CCD) w efekcie będzie prawdopodobnie gorsza od kamery z jednym przetwornikiem 1/2 cala.
Warto jeszcze wspomnieć, że najlepsze pod względem szumów są potencjalnie kamery z CCD przeplotem, najgorsze – kamery CMOS progresywne; różnice pod tym względem będą jednak w obecnych czasach stosunkowo nieduże, tak że kierować należy się raczej jedynie powierzchnią przetwornika i pożądaną rozdzielczością obrazów wynikowych, niż technologią wykonania i zasadą działania przetwornika kamery. Bardzo istotne jest również to, że wykorzystanie możliwości przetwornika o większej przekątnej będzie możliwe tylko wtedy, gdy „dostanie” on odpowiednio dużo światła. A to wiąże się albo z wymogiem posiadania dobrego oświetlenia, albo z wydłużeniem czasu naświetlania poszczególnych klatek, co może powodować rozmazywanie obrazu szybko poruszających się obiektów – coś za coś.
Rozdzielczość i przestrzeń koloru
Wpływ rozdzielczości na jakość obrazu wyjaśniony został w rozdziale poświęconym rozmiarowi przetwornika. W tym rozdziale omówione zostaną tylko formaty rozdzielczości kamer i ich rzeczywista przydatność.
Pewnym anachronizmem z zamierzchłych czasów techniki analogowej jest ciągłe istnienie standardów typu NTSC i PAL. Chociaż standardy te zasadniczo opisywały sposób transmisji informacji o kolorze, to popularnie wiąże się je z pewnymi rozdzielczościami. Zdecydowanie częściej spotykane są kamery zgodne z obowiązującym w Polsce systemem PAL. Z istotnych (z punktu widzenia kamer) informacji, w systemie tym zdefiniowana została przede wszystkim liczba linii, z jakich składa się obraz telewizyjny. W większości odmian tego systemu wynosi ona 625 linii z przeplotem, czyli dwa półobrazy po 312 linii oraz 313 linii. W telewizji część z tych linii nie niesie informacji wizualnej (jedynie np. impulsy wygaszania czy synchronizacji). Użytecznych linii jest jedynie 576 (dwa półobrazy po 288 linii), stąd po digitalizacji (przetworzeniu na postać cyfrową) i zapisaniu w pliku, rozdzielczość pionowa będzie wynosić maksymalnie właśnie 576 linii. Co prawda standard zakłada przenoszenie informacji z przeplotem, ale nic nie stoi na przeszkodzie, żeby sąsiednie półobrazy parami pochodziły z tej samej chwili czasu, czyli były zarejestrowane progresywnie (wymaga to minimalnego rozbudowania układów kamery). Oczywiście z przesyłanego obrazu wybierać można co drugą lub co czwartą linię, aby zmniejszyć wymagania co do mocy obliczeniowej komputera i przepustowości łącz cyfrowych (USB) potrzebnej do poprawnego zarejestrowania obrazu. W standardzie zdefiniowano częstotliwość przesyłu klatek na 25 na sekundę. Jak już wspomniano, w rzeczywistości jest to 50 półobrazów na sekundę – dwa półobrazy składają się na jedną klatkę.
Ostatecznie ze standardem PAL powiązane są następujące rozdzielczości obrazu:
- 768×576 (rozszerzony PAL przystosowany do monitorów komputerowych) – rzadko spotykany,
- 720×576 (tzw. pełen PAL),
- 704×576,
- 720×288 (co druga klatka, za to brak przeplotu),
- 384×288 (proporcje starszych monitorów ekranowych, rzadko dostępny),
- 352×288 (nazywany pół PAL-u),
- 176×144.
Pełen PAL (720×576) z faktycznie istniejącym przeplotem można też interpretować jako 50 klatek/sek. z rozdzielczością 720×288. Daje to obraz bardziej płynny, bez przeplotu, ale z połową rozdzielczości w pionie i wymaga od urządzenia odtwarzającego (lub oprogramowania) umiejętności automatycznej korekcji proporcji boków obrazu (ang. aspect ratio). Niektóre programy odtwarzające pliki wideo są w stanie dokonywać takiej korekcji (np. Media Player Classic), potrafi to robić również oprogramowanie do rejestracji sekwencji wideo firmy DiagNova (np. program DiagnoScope).
System NTSC charakteryzuje się brakiem przeplotu, częstotliwością klatek wynoszącą 30 na sek. i rozdzielczościami będącymi pochodną rozmiaru 640×480:
- 640×480,
- 480×480,
- 640×240,
- 320×240,
- 160×120,
Z punktu widzenia użytkownika kamery, posiadanie kamery w systemie PAL oznacza zwykle, że dostępne są rozdzielczości dające 720 pikseli w linii, oraz że zwykle rozdzielczości powyżej 288 pikseli w pionie wiążą się z wystąpieniem zjawiska przeplotu. Kamery systemu PAL udostępniają zwykle rozdzielczości również systemu NTSC, ale przystosowanie to nie obejmuje z reguły zwiększenia liczby klatek do 30 na sekundę i wyeliminowania zjawiska przeplotu.
Strumień danych
W przypadku kamer cyfrowych rozdzielczość ma jeszcze aspekt związany z przesyłaniem danych. Jedna klatka w formacie pełnego PAL-u (720×576) to 414720 pikseli. Kolor każdego piksela w najprostszy sposób zakodować można podając wartość natężenia każdej składowej podstawowej koloru (RGB – Red Green Blue, czyli czerwonej, zielonej i niebieskiej). Rozsądne założenia jakościowe wymagają podania każdej składowej z rozdzielczością 256 poziomów, czyli na każdą składową trzeba użyć 8 bitów (jednego bajta) danych. W efekcie powoduje to konieczność użycia trzech bajtów do zakodowania koloru jednego piksela i 1244160 bajtów na całą klatkę. Przy 25 klatkach daje to strumień danych równy około 30 MB (megabajtów) na sekundę, co odpowiada maksymalnej użytecznej przepustowości popularnej magistrali USB. Projektanci kamery muszą jednak uwzględnić dodatkowy margines bezpieczeństwa i przy przesyłaniu danych stosują pewien trick. Polega on na wykorzystaniu pewnej ułomności wzroku ludzkiego, dzięki której można zmniejszyć wypadkową liczbę bajtów potrzebnych do zakodowania danych jednego piksela z trzech do dwóch. Wymagania co do strumienia danych wówczas spadają i wideo o rozdzielczości 720×576 może być przenoszone z wykorzystaniem taniej magistrali USB. W tym momencie wypadałoby wprowadzić pojęcie przestrzeni barw.
Przestrzeń barw
Z różnych powodów, m.in. aby zmniejszyć ilość danych, umieścić dodatkowe informacje, dopasować się do możliwości urządzenia, dane w postaci cyfrowej przesyła się w formacie innym od naturalnego, w którym osobno koduje się informacje o natężeniu każdej składowej podstawowej koloru każdego piksela. Dodatkowo, w ramach poprawy jakości, w ostatnich czasach zwiększa się dokładność zapisu każdego koloru i przeznacza się na niego więcej niż – do niedawna uznawane za całkowicie wystarczające – 8 bitów (bajt).
Oprócz tego podstawowego formatu powstało więc wiele formatów pochodnych, jak również i formatów znacząco innych. Nie uwzględniamy tu na razie kwestii algorytmicznego zmniejszania objętości danych – kompresji.
Ze względu na sposób kodowania koloru i liczbę potrzebnych bitów do zakodowania jednego piksela (3 x 8 = 24) format podstawowy nosi nazwę RGB_24. Użyteczne i wykorzystywane praktycznie formaty pochodne formatu podstawowego to:
- RGB_16 (odpowiednio 5, 5 i 5 lub 5, 6 i 5 bitów na poszczególne składowe – w obrazie wyraźnie widoczne pewne artefakty i przekłamania),
- RGB_32 (dodatkowe 8 bitów na informacje o przezroczystości lub zostawione puste w celu przyśpieszenia operacji ze względu na zgodność rozmiaru danych opisujących piksel z rozmiarem rejestrów mikroprocesora),
- RGB_36 (po 12 bitów na składową koloru).
Najczęściej stosowane formaty zasadniczo różne od formatu RGB to formaty typu YUV, gdzie kolor koduje się nie poprzez podanie wartości składowych koloru, a poprzez podanie dla każdego piksela jasności (luminancji – Y) oraz dla jednego lub większej grupy pikseli łącznie koloru (barwy – U i V). Wymienić tu można:
- YUY2 – kolor kodowany łącznie dla par pikseli w poziomie, wypadkowa liczba bitów na jeden piksel – 16,
- UYVY – jak YUY2, ale inna kolejność zapisu danych (nie są kompatybilne),
- YV12 – kolor kodowany dla grup czterech pikseli (po dwa w pionie i w poziomie), wypadkowa liczba bitów na jeden piksel – 12.
- YV9 – kolor kodowany dla grup szesnastu pikseli (po cztery w pionie i w poziomie), wypadkowa liczba bitów na jeden piksel – 9.
Klatki zapisane w danym formacie przestrzeni kolorów można łatwo przekodowywać do innego formatu, zwykle wiąże się to jednak z minimalną utratą jakości koloru. Dla komputera najwygodniejszy jest format RGB i jeśli kamera umożliwia wysyłanie danych w różnych formatach, format RGB_24 powinien zawsze być pierwszym wyborem.
Nie należy jednak obawiać się wykorzystania innych przestrzeni barw. Dla zwykłych zdjęć, a zwłaszcza dla zdjęć medycznych przestrzenie kolorów YUY2 i YV12 nie powodują widocznego pogorszenia barw. Nawet rzadko stosowana przestrzeń YV9 zwykle daje akceptowalną jakość. Na potrzeby tego opracowania przetestowaliśmy użycie różnych przestrzeni kolorów do zakodowania jednej klatki z wideostroboskopu (fałdy głosowe w trakcie fonacji) oraz prostego obrazka syntetycznego, dobranego tak, żeby uwypuklić możliwe zniekształcenia. Wyniki przedstawiono na na rysunkach 7 i 8.
.jpg)
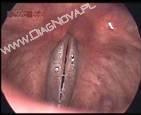
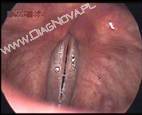
.jpg)
.jpg)
.jpg)



Rys. 7. Porównanie wyglądu klatki z rzeczywistej sekwencji wideo zakodowanej z użyciem różnych przestrzeni barw






Rys. 8. Porównanie wyglądu syntetycznej klatki (o treści tak dobranej, aby wrażliwa była na sposób kodowania koloru) zakodowanej z użyciem różnych przestrzeni barw
O ile specjalne spreparowana klatka z występującymi ostrymi krawędziami oddzielającymi zupełnie inne kolory pokazuje artefakty związane z użyciem skompresowanego sposobu kodowania barwy (rys. 8), to na rzeczywistym obrazie wideo o dosyć jednolitej barwie nie daje się zauważyć wpływu różnych sposobów zapisu informacji o kolorze.
Dodać można, że większość procedur kompresujących jawnie bądź niejawnie konwertuje klatki filmu do postaci YUY2, aby zaoszczędzić miejsca (nawet popularny format, w jakim zapisane są filmy DVD, używa przestrzeni barw YV12, co jest czasem zauważalne w czasie oglądania filmów animowanych). Zysk z użycia w kamerze przestrzeni barw RGB_24 lub RGB_32 widoczny więc będzie praktycznie tylko w przypadku wymuszenia kompresowania filmów z wykorzystaniem przestrzeni barw RGB, w innym przypadku i tak klatka wybierana z filmu w rzeczywistości będzie używała przestrzeni kolorów YUV i kodowania YUY2 lub YV12.
Oprócz zasadniczych różnic pomiędzy formatami przestrzeni barw, dochodzą subtelne różnice związane z naleciałościami z czasów sygnałów analogowych. Niektóre z formatów mogą niestety występować z dodatkowymi zmianami w skali odwzorowania (np. składowe koloru opisywane bajtem (wartości 0–255) mogą zmieniać się jedynie w zakresie 16–240). Algorytmy przetwarzające dane z przetwornika kamery (zawsze w formacie RGB) mogą być zapisane w zgodności z różnymi regulacjami prawnymi. Prowadzi to co prawda do bardzo nieznacznych przekłamań, ale wskazane jest, żeby program komputerowy rejestrujący sekwencje pozwalał na wybór algorytmu dającego najlepszą jakość obrazu (w oprogramowaniu firmy DiagNova umieszczone zostały opcje korekcji tych minimalnych niezgodności, patrz rys. 9).
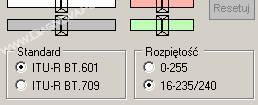
Rys. 9. Zaawansowane opcje wyboru standardu kodowania i dekodowania kolorów w systemie YUY2 (program DiagnoScope)
Przykład wykorzystania tych subtelnych sposobów korekcji obrazu przedstawiony będzie w rozdziałach pokazujących praktyczne aspekty rejestracji obrazu.
Rozdzielczość ponadnormatywna – kamery HD
Od kilku lat wchodząca rynek kamery umożliwiające nagrywanie obrazu w rozdzielczości większej niż standardowe 720×576. Dostępne są rozmaite rozdzielczości, a pierwszym zagadnieniem, które należy rozważyć są proporcje boków uzyskiwanego obrazu (wspominany już aspect ratio). Obraz wideo z kamer klasycznych ma proporcje zwykle równe 4:3 (NTSC, rzadziej PAL) lub 5:4 (PAL). Dopasowane są one do klasycznych telewizorów i monitorów komputerowych starszego typu. Na monitorach panoramicznych obraz albo nie wypełni całego monitora, albo przy wyświetlaniu w trybie rozciągania część obrazu będzie stracona. Obraz taki dobrze nadaje się do rejestracji medycznych danych wideo, gdzie badane obiekty mogą mieć kształt dowolny, a nie rozciągnięty horyzontalnie. Zaletą obrazów HD rozdzielczości o bliskim kwadratowi stosunku boków jest więc dopasowanie do widoku obrazów medycznych. Mogą tu być praktycznie dowolne rozdzielczości, wymienić można:
- 800×600,
- 1024×768,
- 1280×960,
- 1280×1024,
- 1600×1200
i większe.
Z drugiej strony, do dyspozycji są kamery udostępniające rozdzielczości powiązane z rynkiem popularnym, czyli panoramiczne, tj. o proporcjach 16:9 lub 16:10. Mniej pasują one do prezentacji danych medycznych, ale za to lepiej wypełniają przestrzeń nowoczesnych monitorów. Wymienić tu można:
- 1280×720,
- 1280×800,
- 1360×768,
- 1440×900,
- 1680×1024,
- 1920×1080.
Obraz o większej rozdzielczości bezwzględnie wykazuje większą użyteczność, ale są granice tej użyteczności. Bezmyślne kupowanie kamer o maksymalnej rozdzielczości w większości wypadków nie doprowadzi do adekwatnego poprawienia obrazu. Również wykorzystywanie pełnej rozdzielczości takich kamer w wielu przypadkach może dać efekt przeciwny do zamierzonego i sensownym kompromisem jest wykorzystanie rozdzielczości znacznie zmniejszonej. Wspomniane już było, że większa liczba pikseli przekłada się na większe szumy. Większość tych dodatkowych szumów można usunąć na etapie obróbki komputerowej, dokonując zmniejszenia rozdzielczości obrazów. Większość, ale nie wszystkie. Na skutek wspomnianej już ograniczonej przepustowości magistral komputerowych obrazy o większych rozdzielczościach przesyłane są ze znacznie ograniczoną liczbą klatek na sekundę. Redukcja ta wynosić może w przypadku obrazów przenoszonych bez kompresji od 4 razy (w stosunku do 30 klatek/sek. dla obrazu 640×480) dla obrazu 1280×960 (czyli wynikowo 7,5 klatek/sek.) do 16 razy dla obrazu 2560×1920 (czyli ok. 2 klatek/sek.).
Wprowadzenie kompresji transmitowanych danych w celu poprawienia liczby klatek pogarsza z kolei ich jakość, tak że zyski z dodatkowej rozdzielczości są iluzoryczne. Dodatkowo, przy zapisywaniu obrazu o wysokiej rozdzielczości na dysku twardym komputera w postaci pliku wideo ogromny strumień danych spowoduje tworzenie bardzo dużych plików wynikowych (trudnych do zarządzania nimi, w tym do archiwizacji) lub wymagać będzie dużego stopnia kompresji, co dodatkowo pogarsza jakość i czyni nadmierne rozdzielczości bezużytecznymi. W przypadku obrazu HD rozważyć trzeba, choć jest to pewnego typu „cofanie się w rozwoju”, rejestrację nie tylko pełnoprawnych sekwencji wideo, ale i pojedynczych klatek. Nie występuje wówczas problem objętości i wymaganej mocy komputera. Pojawia się wówczas jednak problem opóźnienia rejestracji klatki – przy obserwacji obrazu i wybieraniu klatek „na żywo” od wyboru przez operatora klatki do procesu jej rejestracji mija zwykle około 1/10 s. Powoduje to, że nie jest rejestrowana pożądana klatka, a w rzeczywistości ta następująca kilka klatek po niej. Rozwiązaniem jest tu dostępny jeszcze bardzo rzadko w oprogramowaniu rejestracyjnym (testowo umieszczona jest taka funkcja w programie DiagnoScope) tryb nagrywania krótkich serii klatek (4 do 8).
Kamery HD mają też zwykle większe zapotrzebowanie na ilość potrzebnego światła. Do tego dochodzi poważny problem rejestracji zjawisk szybkozmiennych (np. fałdy głosowe w czasie fonacji). Aby uniknąć rozmazania obrazu i wykorzystać pełną rozdzielczość kamery HD jej migawka musi być od 2 do 4 razy krótsza niż w przypadku zwykłych kamer. Dodatkowo zwiększa to wymagania dotyczące jakości oświetlenia. Podkreślić należy więc raz jeszcze rolę oświetlenia. Dobra kamera HD wymaga doskonałego (głównie bardzo mocnego) oświetlenia. Jest to istotne do tego stopnia, że właściwie można zaryzykować stwierdzenie, że kamera HD przy rejestracji szybkozmiennego obrazu ma sens jedynie w przypadku zastosowania technik stroboskopowych z oświetleniem błyskowym z lampami wyładowczymi o dużej energii błysku.
Ostatnim aspektem stosowania kamer HD jest prezentacja danych. Jeśli zarejestrowane obrazy prezentowane są na ekranie monitora w małym oknie, to nigdy nie wykorzysta się potencjału HD. Występuje to np. w momencie porównywania obrazów obok siebie. Wystarczająca jest wtedy rozdzielczość 640 x 480. Paradoksalnie problem dotyczy również wydruków. Przy założeniu podawanej w piśmiennictwie rozdzielczości normalnego oka w dobrych warunkach oświetleniowych równej około 1 minucie kątowej (oko oddzieli dwa punkty, jeśli ich środki oddalone są co najmniej o jedną minutę kątową, co daje około 0,3 mm z odległości 1 m), oraz prezentacji obrazów w popularnym formacie dwukolumnowym (obrazy o rozmiarze około 7,5 cm szerokości) i ich oglądaniu z odległości 0,5 m – oko ludzkie nie zobaczy ziarnistości już dla klatek o szerokości 500 pikseli! Zakładając oglądanie obrazów z odległości 35 cm, wystarczy rozdzielczość około 700 pikseli, czyli tyle, ile dają klasyczne kamery pracujące w systemie PAL. Możliwości kamery HD będą zupełnie niewykorzystane. Obrazy o większych rozdzielczościach swoją użyteczność wykażą dopiero przy umiejętnym kadrowaniu treści i powiększaniu istotnych elementów obrazu.
Kamery HD mogą być jednak użyteczne nawet bez wykorzystania pełni swoich możliwości, ponieważ ze względu na swoje większe zaawansowanie technologiczne są zwykle progresywne, a to może być znacząca zaleta.
Podsumowując, kamery HD przeznaczone są dla użytkowników którzy:
- rejestrują obrazy statyczne (preparaty mikroskopowe itp.), albo
- rejestrują obrazy ruchome i mają doskonałe źródło światła o dużej mocy, albo
- rejestrują obrazy szybkozmienne i mają dobre źródło światła stroboskopowego,
- dokonują kadrowania prezentowanych danych,
- wymagają kamery progresywnej,
- mają szybki komputer i dużo miejsca na filmy albo zaawansowane oprogramowanie zdolne najlepiej do rejestrowania serii klatek,
- nie wymagają dużej płynności obrazu wideo (zadowala ich mała liczba klatek na sekundę).
W pozostałych sytuacjach lepszym wyborem będzie kamera klasyczna. Należy tu odróżnić wybór między kamerą HD a klasyczną od wyboru miedzy kamerą cyfrową a analogową. To zupełnie inne sprawy.
Naszym zdaniem, dla większości osób rejestrujących medyczny obraz wideo optymalnym rozwiązaniem byłaby kamera progresywna o rozdzielczości 800×600 pikseli, ew. 640×480, z przetwornikiem o rozmiarze 1/3 cala. Dla osób o największych wymaganiach – kamera o rozdzielczości 1280×960 z przetwornikiem 1/2 cala. Przetworniki o większych rozmiarach mogą sprawiać problemy ze stworzeniem optyki endoskopowej zdolnej poprawnie wykorzystać ich możliwości, zaś większe rozdzielczości będą praktycznie nie do wykorzystania w codziennym użytkowaniu poza rejestracją obrazów całkowicie statycznych (preparaty mikroskopowe, zdjęcia dna oka itp.).
Kamery jednoprzetwornikowe a trójprzetwornikowe (3CCD)
Różnica między tymi typami kamer została już wstępnie opisana w rozdziale poświęconym powierzchni przetwornika. Dodać należy tylko, że użycie trzech przetworników monochromatycznych (po jednym dla każdej składowej koloru) zamiast jednego przetwornika z mozaiką kolorów minimalnie poprawia jakość odwzorowania kolorów z powodu możliwości zastosowania lepszych filtrów rozdzielających kolory. Aktualnie dla nowych kamer różnica ta jest jednak minimalna.